上海交通大学的武筱林教授和他的博士生张熙近期完成了一项研究,他们发现,通过学习,机器可以通过照片分辨出谁是罪犯,谁是守法公民,识别准确率在86%以上。 这篇论文题为《基于面部图像的自动犯罪概率推断》(Automated Inference on Criminality using Face Images),目前上传在预印本网站arXiv上。他们运用计算机视觉和机器学习技术检测1856张中国成年男子面部照片,其中将近一半是已经定罪的罪犯。实验结果显示,通过机器学习,分类器可以以较高概率区分罪犯与非罪犯这两个群体的照片。特别是在内眼角间距、上唇曲率和鼻唇角角度这三个测度上,罪犯和非罪犯存在较为显著的差距。平均来讲,罪犯的内眼角间距要比普通人短5.6%,上唇曲率大23.4%,鼻唇角角度小19.6%。同时,他们发现罪犯间的面部特征差异要比非罪犯大。 从古至今,从西方到东方,我们都能看到类似于“相由心生”的说法。但不论是相士或是从事相应研究的心理学家,都始终摆脱不了“迷信”或“歧视”的帽子。武筱林和张熙出于好奇,试图利用数据分析推翻这门古老的“伪科学”,但研究出来的结果令他们大吃一惊。更令他们始料未及的是,文章一经公开,就招来了漫天争议。 武筱林11月30日告诉澎湃新闻,他收到了很多邮件,虽然绝大部分是国际上的研究者来信索取数据和实验细节,进行学术层面的交流,但也有不少不友好的评论,甚至指责他的研究是对社会“不负责任”。
武筱林 “我们的运气也不好,文章刚出来的时候正好是特朗普当选前后。有来自美国的邮件说,‘美国现在已经一团糟了,你们就别添乱了’。 ”也有人直接建议武筱林撤稿。对于被贴上“歧视”的标签,武筱林有些恼火,他强调,他个人的价值观绝对是反歧视的,而他做这个研究的原本目的是证伪。 此外,他也收到了一些令人哭笑不得的评论,比如有的网友想让他把这个东西交给纪检委使用。 武筱林告诉澎湃新闻,他目前还是打算专心把这个工作进一步做得更严谨、更充分,这项研究的成熟程度离应用还很遥远,他们目前也没有任何走向应用的打算。 “从另一个角度讲,我们的研究也可能为反歧视提供依据”。但他也坦言, 人工智能研究应如何划定价值伦理的禁区,是个很严肃的问题,光凭他个人难以回答。 “现在世界范围里都存在这样的争论,人工智能已经发展到这一步了。” 那么,武筱林和张熙的这项研究,到底是怎么进行的呢? 通过学习,机器辨认出罪犯照片的准确率在86%以上 实验选取了1856张中国18到55岁男性的照片,面部无毛发遮挡、无伤疤或其他标记,并将它们归为罪犯组和非罪犯组。非罪犯组包含1126张用“网页蜘蛛”从互联网上抓取的照片,人群来自社会各行各业:服务员、建筑工人、司机、医生、律师、教授等。罪犯组共730张照片,其中330张来自公安部或省级公安厅的通缉令,400张由一所与实验组达成保密协议的公安局提供。在这730名罪犯中,235名涉及暴力犯罪,包括谋杀、强奸、人身侵犯、绑架和抢劫,其余则犯下了偷窃、欺诈、贪污等非暴力罪行。所有照片都被调整为80cmX80cm大小,并对亮度和灰比都进行了控制,尽量避免对结果造成影响。
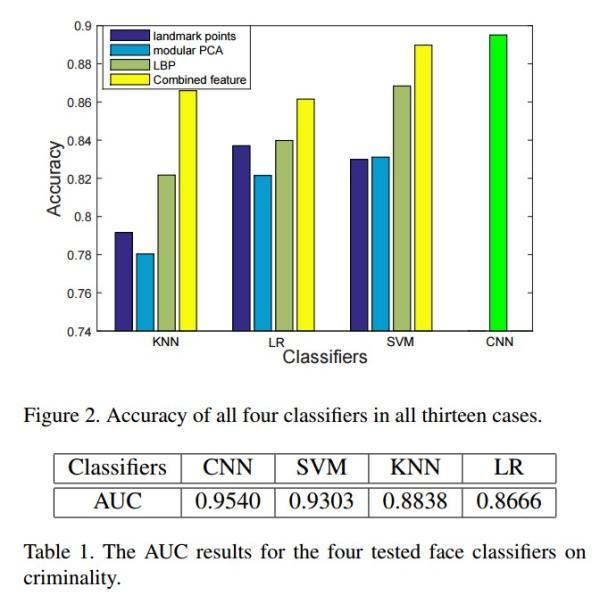
研究使用的照片样本。a组为罪犯,b组为非罪犯。 实验用4种分类器(逻辑回归,KNN,SVM,CNN)对样本进行检测,发现它们都能较成功地对罪犯和非罪犯组进行分类,准确率在86%以上。
4种分类器的准确率。 武筱林和张熙进一步发现,罪犯和非罪犯在面部特征方面最显著的差别在内眼角间距、上唇曲率和鼻唇角角度这三个测度上。平均来讲,罪犯的内眼角间距要比普通人短5.6%,上唇曲率大23.4%,鼻唇角角度小19.6%。
图b标注了存在差异性的3个特征点。表4为罪犯组和非罪犯组在3个特征点上的平均值和偏离值。 (责任编辑:人才市场) |